Optimal Leaf Ordering
What this program does - An example
As said in the Background page, the Optimal Clustering "optimizes" the clustering output on a sample data by
minimizing the differences (or maximizing the similarity - generated and calculated in terms of the distance) amongst a given number of data. This
is done by applying the optimization algorithm in the Hierarchical cluster generated by (in our case) UPGMA algorithm.
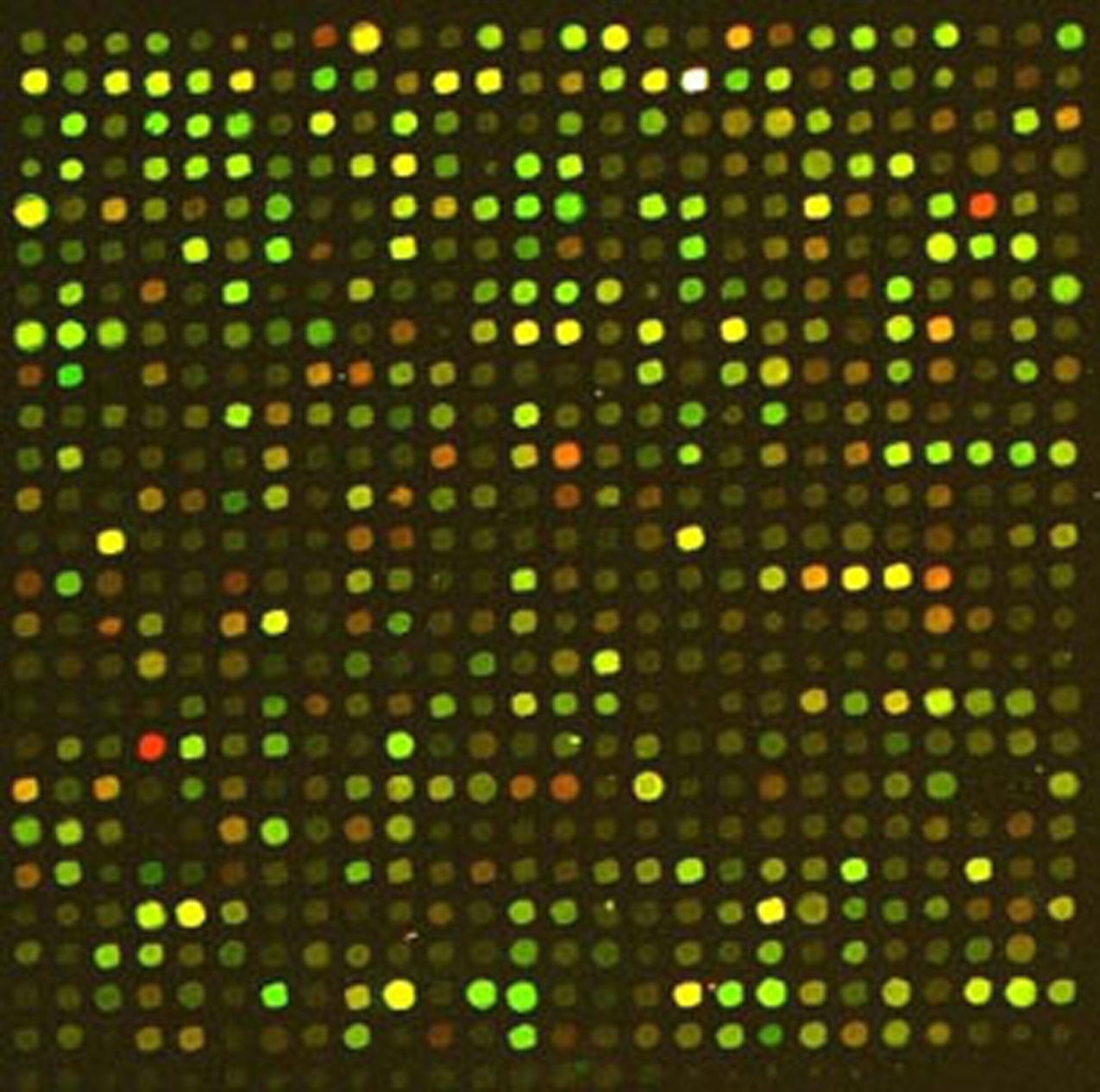
By using Input1.txt file, as sample data, we obtained these outputs.



Input1 data
UPGMA output
Optimal Ordering Output
It might be important to note that the Hierarchical Clustering output above is different from the ones generated by Ziv B.J. et. al. This is most likely because the in our algorithm, we used the 'Manhattan Distance' formula (which is most likely not what Ziv B. J. et. al used).